Spark Streaming + Kafka 入门实例
2016-11-23 09:54:36 作者:MangoCool 来源:MangoCool
初学Spark Streaming和Kafka,直接从网上找个例子入门,大致的流程:有日志数据源源不断地进入kafka,我们用一个spark streaming程序从kafka中消费日志数据,这些日志是一个字符串,然后将这些字符串用空格分割开,实时计算每一个单词出现的次数。
部署安装zookeeper:
1、官网下载zookeeper:http://mirror.metrocast.net/apache/zookeeper/
2、解压安装:
tar -zxvf zookeeper-3.4.8.tar.gz
3、配置conf/zoo.cfg:
dataDir=/home/hadoop/data/zookeeper/data # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=h181:2889:3889 maxSessionTimeout=1200000
4、启动,到zookeeper的bin目录下执行命令:
./zkServer.sh start ../conf/zoo.cfg 1>/dev/null 2>&1 &
5、可以用ps命令是否启动:
ps -ef|grep zookeeper
部署安装Kafka:
1、官网下载kafka:https://kafka.apache.org/downloads
2、解压安装:
tar -zxvf kafka_2.11-0.10.1.0.tgz
3、配置:
config/server.properties:
broker.id=0 listeners=PLAINTEXT://h181:9092 advertised.listeners=PLAINTEXT://h181:9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/tmp/kafka-logs num.partitions=1 num.recovery.threads.per.data.dir=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=h181:2181 zookeeper.connection.timeout.ms=6000
这里只修改了listeners、advertised.listeners、zookeeper.connect。
config/consumer.properties:
zookeeper.connect=h181:2181 # timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=6000 #consumer group id group.id=test-consumer-group
4、启动,到kafka的bin目录下执行命令:
./kafka-server-start.sh ../config/server.properties 1>/dev/null 2>&1 &
5、可以用ps命令是否启动:
ps -ef|grep kafka
示例程序:
依赖:jdk1.7,spark-2.0.1,kafka_2.11-0.10.1.0,zookeeper-3.4.8,scala-2.118
开发环境:ideaIU-14.1.4
测试环境:win7
建立maven工程KafkaSparkDemo,在pom.xml配置文件添加必要的依赖:<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>kafka-spark-demo</groupId>
<artifactId>kafka-spark-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.0.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
</dependencies>
</project>
KafkaSparkDemo对象:
package com.mangocool.kafkaspark
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Duration, StreamingContext}
/**
* Created by MANGOCOOL on 2016/11/11.
*/
object KafkaSparkDemo {
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir", "E:\\Program Files\\hadoop-2.7.0")
System.setProperty("HADOOP_USER_NAME","hadoop")
System.setProperty("HADOOP_USER_PASSWORD","hadoop")
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("kafka-spark-demo")
val scc = new StreamingContext(sparkConf, Duration(5000))
scc.sparkContext.setLogLevel("ERROR")
scc.checkpoint(".") // 因为使用到了updateStateByKey,所以必须要设置checkpoint
val topics = Set("kafka-spark-demo") //我们需要消费的kafka数据的topic
val brokers = "192.168.21.181:9092"
val kafkaParam = Map[String, String](
// "zookeeper.connect" -> "192.168.21.181:2181",
// "group.id" -> "test-consumer-group",
"metadata.broker.list" -> brokers,// kafka的broker list地址
"serializer.class" -> "kafka.serializer.StringEncoder"
)
val stream: InputDStream[(String, String)] = createStream(scc, kafkaParam, topics)
stream.map(_._2) // 取出value
.flatMap(_.split(" ")) // 将字符串使用空格分隔
.map(r => (r, 1)) // 每个单词映射成一个pair
.updateStateByKey[Int](updateFunc) // 用当前batch的数据区更新已有的数据
.print() // 打印前10个数据
scc.start() // 真正启动程序
scc.awaitTermination() //阻塞等待
}
val updateFunc = (currentValues: Seq[Int], preValue: Option[Int]) => {
val curr = currentValues.sum
val pre = preValue.getOrElse(0)
Some(curr + pre)
}
/**
* 创建一个从kafka获取数据的流.
* @param scc spark streaming上下文
* @param kafkaParam kafka相关配置
* @param topics 需要消费的topic集合
* @return
*/
def createStream(scc: StreamingContext, kafkaParam: Map[String, String], topics: Set[String]) = {
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](scc, kafkaParam, topics)
}
}
直接运行程序:
因为kafka队列里面还没有消息,所以为空。
启动kafka-console-producer工具,手动往kafka中依次写入如下数据:
./kafka-console-producer.sh --topic kafka-spark-demo --broker-list h181:9092

结果如下:
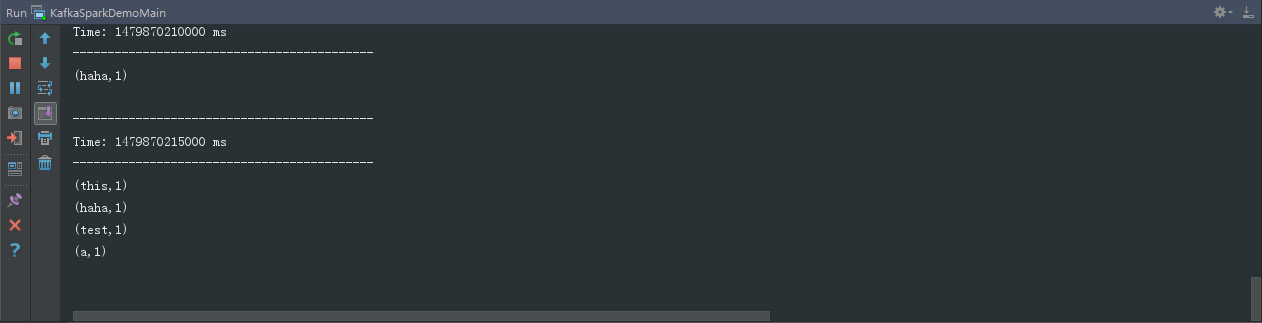
注:这里的broker-list的主机别用localhost,不然可能会遇到以下错误:
[hadoop@h181 bin]$ ./kafka-console-producer.sh --topic kafka-spark-demo --broker-list localhost:9092 hh [2016-11-22 17:09:34,539] ERROR Error when sending message to topic kafka-spark-demo with key: null, value: 2 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback) org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.如果broker-list的端口不对,会遇到以下错误:
Exception in thread "main" org.apache.spark.SparkException: java.nio.channels.ClosedChannelException at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$checkErrors$1.apply(KafkaCluster.scala:366) at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$checkErrors$1.apply(KafkaCluster.scala:366) at scala.util.Either.fold(Either.scala:98) at org.apache.spark.streaming.kafka.KafkaCluster$.checkErrors(KafkaCluster.scala:365) at org.apache.spark.streaming.kafka.KafkaUtils$.getFromOffsets(KafkaUtils.scala:222) at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:484) at com.dtxy.xbdp.test.KafkaSparkDemoMain$.createStream(KafkaSparkDemoMain.scala:54) at com.dtxy.xbdp.test.KafkaSparkDemoMain$.main(KafkaSparkDemo.scala:31) at com.dtxy.xbdp.test.KafkaSparkDemoMain.main(KafkaSparkDemo.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
你还可以用程序写入数据到kafka。
KafkaProducer类:
package com.mangocool.kafkaspark;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
/**
* Created by MANGOCOOL on 2016/11/23.
*/
public class kafkaProducer extends Thread {
private String topic;
public kafkaProducer(String topic){
super();
this.topic = topic;
}
@Override
public void run() {
Producer producer = createProducer();
int i=0;
while(true){
producer.send(new KeyedMessage<Integer, String>(topic, "message: " + i++));
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private Producer createProducer() {
Properties properties = new Properties();
properties.put("zookeeper.connect", "h181:2181");//声明zk
properties.put("serializer.class", StringEncoder.class.getName());
properties.put("metadata.broker.list", "h181:9092");// 声明kafka broker
return new Producer<Integer, String>(new ProducerConfig(properties));
}
public static void main(String[] args) {
new kafkaProducer("kafka-spark-demo").start();// 使用kafka集群中创建好的主题 kafka-spark-demo
}
}
文章就此结束,如有错误欢迎指正和交流!
文章参考:http://qifuguang.me/2015/12/24/Spark-streaming-kafka%E5%AE%9E%E6%88%98%E6%95%99%E7%A8%8B/
http://chengjianxiaoxue.iteye.com/blog/2190488
标签: Spark Streaming Kafka demo 例子
分享: