java.lang.IllegalArgumentException: requirement failed: Column features must be of type org.apache.spark.mllib.linalg.VectorUDT@f71b0bce but was actually org.apache.spark.ml.linalg.VectorUDT@3bfc3ba7.
2016-10-17 11:39:13 作者:MangoCool 来源:MangoCool
在上一个例子中,关于Spark-2.0.1 GaussianMixture示例代码,原本spark是2.0.0版本的,但是该例子只要将操作设置到pipeline的stage中执行,就会报错:
Exception in thread "main" java.lang.IllegalArgumentException: requirement failed: Column features must be of type org.apache.spark.mllib.linalg.VectorUDT@f71b0bce but was actually org.apache.spark.ml.linalg.VectorUDT@3bfc3ba7. at scala.Predef$.require(Predef.scala:224) at org.apache.spark.ml.util.SchemaUtils$.checkColumnType(SchemaUtils.scala:42) at org.apache.spark.ml.clustering.GaussianMixtureParams$class.validateAndTransformSchema(GaussianMixture.scala:64) at org.apache.spark.ml.clustering.GaussianMixture.validateAndTransformSchema(GaussianMixture.scala:275) at org.apache.spark.ml.clustering.GaussianMixture.transformSchema(GaussianMixture.scala:342) at org.apache.spark.ml.Pipeline$$anonfun$transformSchema$4.apply(Pipeline.scala:180) at org.apache.spark.ml.Pipeline$$anonfun$transformSchema$4.apply(Pipeline.scala:180) at scala.collection.IndexedSeqOptimized$class.foldl(IndexedSeqOptimized.scala:57) at scala.collection.IndexedSeqOptimized$class.foldLeft(IndexedSeqOptimized.scala:66) at scala.collection.mutable.ArrayOps$ofRef.foldLeft(ArrayOps.scala:186) at org.apache.spark.ml.Pipeline.transformSchema(Pipeline.scala:180) at org.apache.spark.ml.PipelineStage.transformSchema(Pipeline.scala:70) at org.apache.spark.ml.Pipeline.fit(Pipeline.scala:132) at com.dtxy.xbdp.widget.algorithm.GaussianMixtureWidget.fit(GaussianMixtureWidget.scala:64) at com.dtxy.xbdp.test.GaussianMixtureWidgetTest$.main(GaussianMixtureWidgetTest.scala:105) at com.dtxy.xbdp.test.GaussianMixtureWidgetTest.main(GaussianMixtureWidgetTest.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
也就是在数据构造Vector向量后,发现并不是后面所要的,所以在checkColumnType中报错了。即便你是构造出mllib包下的VectorUDT,也不行,依然报错:
VectorAssembler does not support the org.apache.spark.mllib.linalg.VectorUDT@f71b0bce type看到这个错,估计你有点手足无措了,没办法只能看源码了,先找到报错位置:
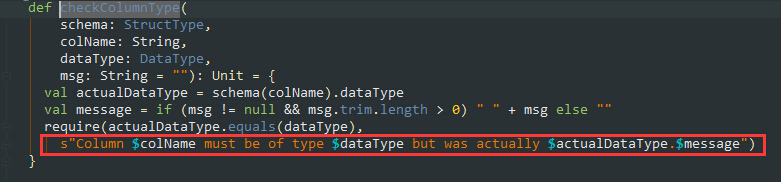
然后往上一层看,看看在checkColumnType这个方法里面,传参datatype是什么类型的:
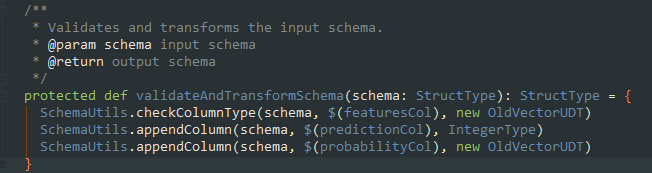
看到这里总算是明白了,原来在调用的时候构造了一个OldVectorUDT,怪不得报错类型不对,这算是spark-2.0.0的一个bug吧。
google了一下,发现spark-2.0.1版和spark-2.0.0版的对比:
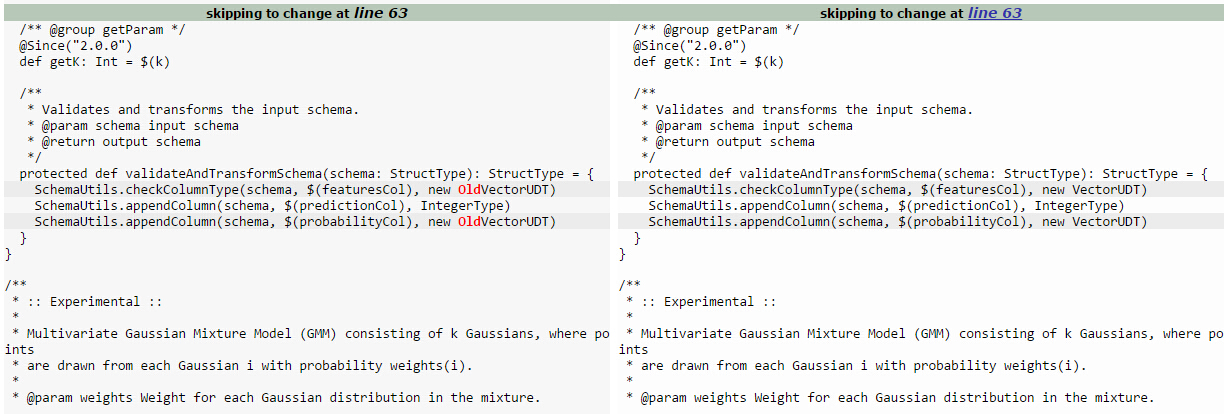
发现最新版本spark-2.0.1已经对该bug做了修复,总算是轮不到自己改源码,hoho。
最后提示一下,解决该问题的办法:升级版本到spark-2.0.1,感谢浏览,欢迎交流!
分享: